
Les derniers pilotes Catalyst ont la version 7.12 (le numéro interne des Cat7.12 est le 8.442.0.0 – c’est pas un téléphone ok!). Mais exactement comme les 7.11, ces drivers ont un bug dans la gestion des lumières dynamiques en GLSL. Mais cette fois-ci, je me suis mis à la recherche du bug car il est un peu, voire très génant pour les demos Demoniak3D. J’ai donc pondu un petit script Demoniak3D qui met en évidence ce bug. Ce script montre un mesh plan éclairé par une lumière dynamique. Un appui sur la touche SPACE permet de changer de shader GLSL: on passe du shader bogué au shader corrigé et inversement.
– L’image suivante montre le plan éclairé avec le shader corrigé:
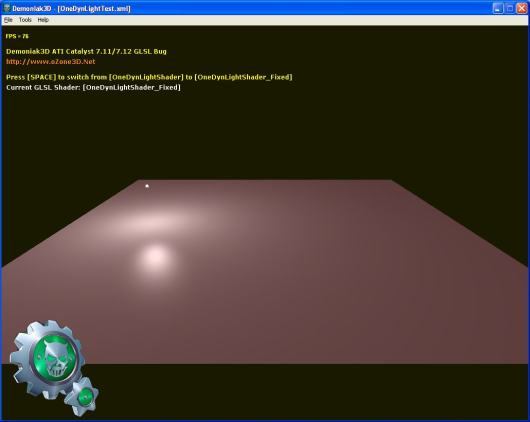
– L’image suivante montre le plan éclairé avec le shader bogué:
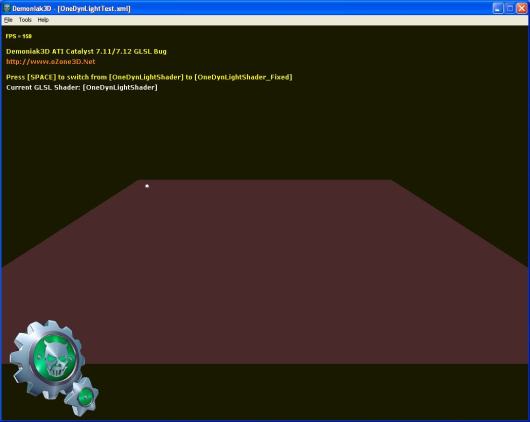
okay tout ceci est bien, mais d’oû vient le bug? Après avoir passé un peu de temps à tweaker les shaders, j’en suis arrivé à la conclusion que le bug se situe au niveau de la valeur contenue dans la variable uniforme built-in gl_LightSource[0].position. Au niveau du vertex shader, cette variable contient la position de la lumière exprimée l’espace de la caméra. C’est OpenGL qui effectue cette transformation, à notre niveau il suffit de spécifier la position de la lumière en coordonnées du monde. Au niveau du vertex shader, gl_LightSource[0].position nous permet de calculer la direction de la lumière utilisée plus tard dans le pixel shader:
lightDir = gl_LightSource[0].position.xyz - vVertex;
Avec la Radeon HD 3870 et les Catalyst 7.11 et 7.12, la valeur contenue dans gl_LightSource[0].position est fausse.
Donc le workaround que je propose en attendant que la driver team d’ATI corrige le bug, est de passer au vertex shader la position de la lumière exprimée dans les coordonnées du monde ainsi que la matrice de vue de la camera et de faire la transformation à la main:
vec3 lightPosEye = vec3(mv * vec4(-150.0, 50.0, 0.0, 1.0));
lightDir = lightPosEye - vVertex;
mv représente la matrice 4×4 de vue de la caméra et vec4(-150.0, 50.0, 0.0, 1.0) représente la position de la lumière en coordonnées du monde.
Au niveau pipeline fixe, les lumières dynamiques sont bien gérées comme le montre l’image suivante:

Au niveau de la démo Demoniak3D, le shader GLSL bogué est appelé OneDynLightShader et celui corrigé OneDynLightShader_Fixed. Le code source de la démo Demoniak3D se trouve dans le fichier OneDynLightTest.xml. Pour lancer la demo, dézippez l’archive dans un répertoire
et lancez DEMO_Catalyst_Bug.exe.
La démo est téléchargeable ici: Demoniak3D Catalyst 7.11/7.12 Bug
Ce bug affecte toutes les radeons MAIS sous Windows XP uniquement. On dirait qu’ATI nous force un peu la main pour passer sous Vista. Pas trop sympa… Ou alors ATI commence à implémenter OpenGL 3.0 dans les drivers XP. Car n’oublions pas qu’avec OpenGL 3.0, tout comme avec DX10, les fonctions fixes du pipelines 3D comme la gestion des lumières dynamiques sont supprimées.
Je voudrais remercier la communauté WorldPCSpecs pour les tests. Merci les gars!






