
Category Archives: Tools de JeGX
FurMark Fume les Cartes Graphiques
Je suis tombé sur ce fil de discussion chez [H]ard|Forum où l’on peut lire ceci:
“That fur demo is known to get cards the hottest, it is also known for smoking cards as well (it was the last thing run for a number of people on the extremesystems forums).”
En gros ça dit que le FurMark est connnu pour faire le plus chauffer les cartes mais qu’il aussi connu pour les faire fumer et c’est souvent la dernière chose que certains utilisateurs aient vu! Je savais que le FurMark était bon pour faire chauffer les cartes mais je ne savais pas qu’il était aussi capable de les détruire. Je sens que cet été va être chaud pour certaines cartes graphiques…
GPU Caps Viewer en Chine
GPU Caps Viewer est en train de se balader un peu partout autour de la planète web, et je viens de le découvir en Chine où il a posé ses valises le temps de faire chauffer quelques GPUs chinois…
Le lien: www.greendown.cn
Attention aux yeux, ça clignote de partout!
GPU Caps Viewer Validation Facility
Compétition d’overclocking GPU
Le site www.hardware.info propose une compétition d’overclocking de GPU et utilise le Fur Rendering Benchmark comme utilitaire principal (bon c’est ma version des faits vu que tout est écrit en néerlandais mais je ne dois pas me tromper de beaucoup – si quelqu’un comprend cette langue, merci d’avance pour un petit feedback de ce qui s’y raconte). Décidément, le fur benchmark fait parler de lui ces derniers temps. Mais le truc marrant c’est que tout le monde s’obstine à utiliser la version 1.0.0 alors que la version 1.1.0 existe…

Fur Rendering Benchmark Used in a Review
Funny, my furry benchmark has been used in a graphics card review along with 3DMark or Lost Planet. Pretty cool 😉
Catalyst 7.9, Radeon 2900 and Surface Deformer
From oZone3D.Net Forums, the Catalyst 7.9 seems to unleash ATI Radeon 2900 GPU. The Surface Deformer benchmark is a benchmark that requires a lot of vertex processing horse power. With Catalyst prior to 7.9, the score of an ATI 2900 was around 8000 o3Marks (that was already high). Now with Catalyst 7.9, the 2900 gets a score of 15000 o3Marks. Incredible!!! Why such a big big jump in OpenGL performance ?
My first thought is that ATI has managed to use correctly the unified arch of the R600 gpu. With unified arch, the workload is distribued over all shaders processors no matter the type of the shader prog (vertex or pixel). So if the vertex shader needs more processing power than the pixel shader, more shaders processors will be used for the vertex shader. My second thought: unified arch has involved new kernel code for catalyst and simply ATI has optimized the R600 codepath. A driver for a modern GPU like the R600 is a very complex piece of code and optimizing such a code is a huge task….
Fur Rendering Benchmark
I officially released the fur rendering benchmark 4 days ago. So let’s analyze a little bit the first feedbacks available on forums over the web.

Homepage: www.ozone3d.net/benchmarks/fur/
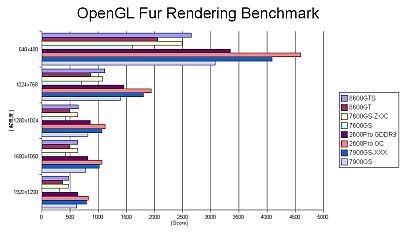
1 – Fur rendering benchmark isn’t cpu dependent and this is a very good thing for a graphics card benchmark. No matter the cpu speed, the result for a given card stays equivalent:
– oZone3D.Net forums
– extremeoverclocking.com forums
– extremeoverclocking.com forums
“yes the first propper gpu bench ive come across, i really like this…. it stops all the arguments about memory timings and cpu speeds. its a good equaliser as all our systems can provide that 10% cpu info the gpu needs…”
2 – 8800GTX vs 2900XT
ATI 2900XT seems to beat NVIDIA 8800GTX. In all forums, the 2900XT is ahead:
– oZone3D.Net forums
– overclockers.co.uk forums
– extremeoverclocking.com forums
3 – this benchmark seems to nicely overload the graphics card and then is a cool GPU burner and stress/stability test utility.
– clubic.com forums : “Par contre j ai jamais vu ma carte graphique chauffer autant: environ 100° pendant la test:ouch:”
– oZone3D.Net forums: “This thing just succeeded to shut down twice the PSU, caused by overloading of the graphics board!!”
I done a little test with my 8800GTX:
– gpu core temp at rest: 58°C
– gpu core temp at load: 83°C

Okay, that’s all for that small benchmark. :winkhappy:
Dynamic branching and NVIDIA Forceware Drivers
Several weeks ago, I posted on Beyond3D a thread on my dynamic branching benchmark. I wondered why dynamic branching performances on Geforce 7 were worse than ones on Geforce 6 or 8. I believe I’ve got the answer: Forceware drivers.
Here are some new results where ratio = Branching_ON / Branching_OFF :
7600GS – Fw 84.21 – Branching OFF: 496 o3Marks – Branching ON: 773 o3Marks – Ratio = 1.5
7600GS – Fw 91.31 – Branching OFF: 509 o3Marks – Branching ON: 850 o3Marks – Ratio = 1.6
7600GS – Fw 91.36 – Branching OFF: 508 o3Marks – Branching ON: 850 o3Marks – Ratio = 1.6
7600GS – Fw 91.37 – Branching OFF: 509 o3Marks – Branching ON: 850 o3Marks – Ratio = 1.6
7600GS – Fw 91.45 – Branching OFF: 509 o3Marks – Branching ON: 472 o3Marks – Ratio = 0.9
7600GS – Fw 91.47 – Branching OFF: 509 o3Marks – Branching ON: 472 o3Marks – Ratio = 0.9
7600GS – Fw 93.71 – Branching OFF: 508 o3Marks – Branching ON: 474 o3Marks – Ratio = 0.9
7600GS – Fw 97.92 – Branching OFF: 505 o3Marks – Branching ON: 478 o3Marks – Ratio = 0.9
7600GS – Fw 100.95 – Branching OFF: 508 o3Marks – Branching ON: 480 o3Marks – Ratio = 0.9
my conclusion is: dynamic branching in OpenGL works fine (read the performance are better than without dynamic branching: ratio > 1) for forceware < = 91.37. For the drivers >= 91.45, the ratio drops under 1. Dynamic branching works as expected for gf6 and gf8 but not for gf7 since forceware 91.45. So the bug explanation is a plausible answer (and it’s easily understandable: in this news we learnt that a forceware driver is made of around 20 millions of lines of code – a paradise for a small bug!!!). I’ve also done the test with the simple soft shadows demo provided with the NV SDK 9.5. The results are the same.
I’ve just done the bench with a 7950gx2 and the latest forceware 160.02 and dynamic branching is still buggy…
Quick Review – GPU Caps Viewer
GPU Caps Viewer is the new I worked on these last days. It’s the successor of HardwareInfos. GPU Caps Viewer is based on the branch v3.x of the oZone3D engine (while HardwareInfos is an oZone3D v.2.x branch based tool). In addition to classic GPU/CPU information / capabilities, GPU Caps Viewer offers two cool features:
– an OpenGL Extensions database. Either you can see the extensions supported by the current graphics card or you can see all existing extensions no matter the graphics board you have. You can quickly select an extension and jump directly to ist webpage (SGI or NVIDIA extensions specs). I must confess it’s very useful for me.
– a GPU-Burner… that was the hard-coding part of GPU Caps Viewer. The GPU-Burner allows to open several 3D windows. Actually you can open as many 3D views you want (1, 2, 4, 6, 10, 20, …). Each view renders a GLSL toon-shaded object with vsync disabled. You can set the size of each window individually (default size is 400×400). Each 3D view is rendered in its own thread… I let you imagine how hard is to debug a multitreaded gfx application :raspberry: And because I’m only a human, there are always some bugs in my code. But there is a very cool tool that helped me to manage the mad threads: ProcessExplorer :thumbup: You can download it here: www.majorgeeks.com/Process_Explorer_d4566.html.

Here an screenshot of my desktop with 13 instances of the 3D view runing at the same time. I will release GPU Caps Viewer very very soon. So stay tuned! :winkhappy:
Ambient Occlusion Generator
I’m currently working on a new algorithm for the ambient occlusion generator. The basic idea comes from smash, the main coder of Fairlight, a famous demoscene group (thank you mate!). My old AmbOccGen was (is still) really slow: calculating per-vertex AO term for a 40000-polys object with 1000 samplers could take many hours and even more (days!). The following image shows a 40,000 polys scene (each torus has 20,000 polys) and the new alogrithm took only 5 minutes to compute the ambient occlusion for 8192 samples! Really cool and I know I can do better…

I’ll released an end-user tool when the new version of oZone3D will be ready. The new version of oZone3D is now a top priority task (and a particularly huge task…).